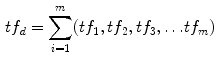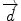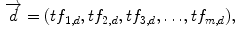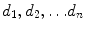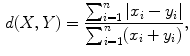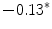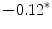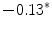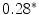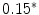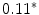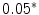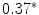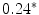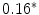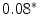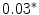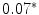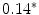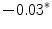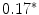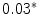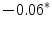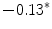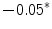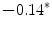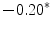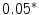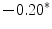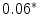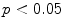Representing Organizational Uncertainty
occurrences extracted from the whole corpus without replacement. The probability distribution for a sampling without replacement under the hypothesis of independence is the hypergeometric distribution (Ayuso et al. 2002), which contrasts with the binomial distribution (with replacement). Or in other words, the “probability of obtaining k items, of one out of two categories, in a sample of n items extracted without replacement from a population of N items that has 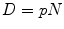 items of that category (and
items of that category (and 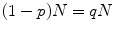 items from the other category)” (Marques de Sá 2007).
items from the other category)” (Marques de Sá 2007).
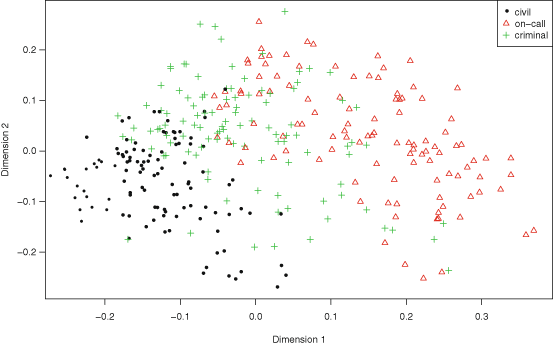
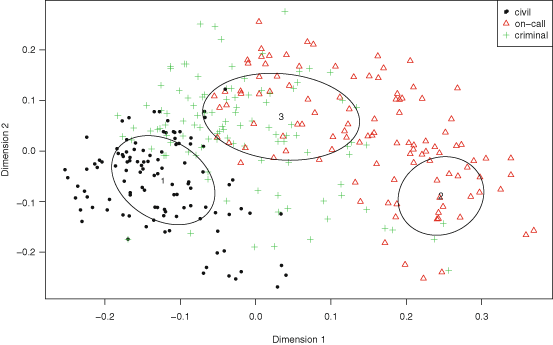
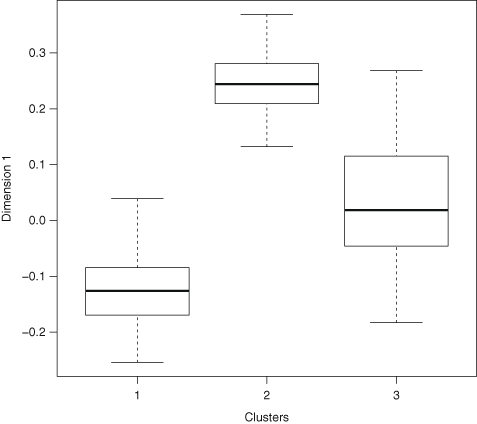
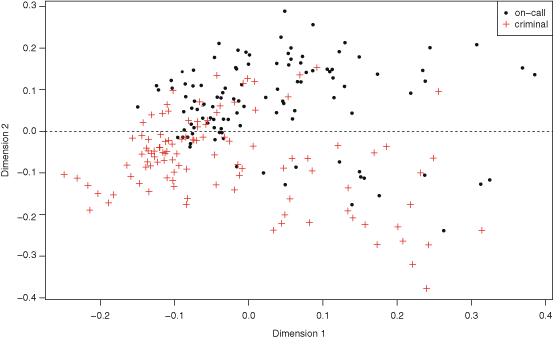
Results showed that the word guardia [on-call] turned out to be over-represented in the subcorpus JJ, the one from junior judges. Furthermore, this over-representation was found to be significant (Ayuso et al. 2003).
The data available in that survey, though, were limited. Questions were general, not specific, and answers were too short to allow any further text exploration. This led to our current survey on Spanish junior judges, which, on one hand, was specifically focused on junior judges, and on the other was designed to gather the types of problems that sprang from on-call situations.
Having rich textual data—part of it specifically focused on on-call problems—permits a variety of research strategies in order to both gather relevant data for modelling a knowledge base, and advance in our understanding of the problems faced by judges at courts when on-call.
5.2.1 Corpora
In order to carry out our analysis, we use three different textual corpora. These are composed by the set of responses to the open-ended questions contained in our survey. In particular, these questions were:
A question about the main types of problems regarding civil issues during the first appointment.
A question about the main types of problems regarding criminal issues during the first appointment.
A question about the main types of problems during on-call periods.
Since interviews were recorded, each answer was literally transcribed and saved in a different text file. Thus we have three different corpora (i.e., sets of responses) that contain a number of text files, each of which representing a single answer to a particular question. The three corpora are thus named and described:
civil: The collection of all responses regarding problems about civil issues, each document representing one single answer. It contains 111 responses out of 118 interviewed judges. Out of the 7 lacking respondents, 4 did not accept a recording, while 3 were not able to recall a single civil problem during the interview.
criminal: The collection of all responses regarding problems about criminal issues, each document representing one single answer. It contains 109 responses out of 118 possible responses. Out of the 9 lacking responses, 4 were due to non recorded interview, while 5 respondents were not able to recall any problem specifically related to criminal issues.
on-call: The collection of all responses regarding problems about on-call issues, each document representing one single answer. It contains 110 responses out of 118. As already noted, half of them were not recorded, while the other half were not able to recall any on-call problem at that moment.
Finally, Table 5.1 summarizes the state of each corpus regarding respondents and non-respondents.
Table 5.1
Number of respondents and non respondents for each corpus
Corpus | Responses | |||
|---|---|---|---|---|
Expected | No record | No answer | Actual | |
Civil | 118 | 4 | 3 | 111 |
Criminal | 118 | 4 | 5 | 109 |
On-call | 118 | 4 | 4 | 110 |
Total | 354 | 12 | 12 | 330 |
5.2.2 Text as Data
Our hypotheses involve, on one hand, testing whether our textual corpora (civil, criminal, and on-call problems) are significantly different from each other, and on the other exploring the content of these corpora in a systematic way. Note that in both cases we treat text as data. We assume that the significant differences among documents can be reduced to differences in the use of language in the documents. Specifically, if two documents refer to different topics (e.g. they refer to different kinds of problems), these differences can appear in both the types of words they contain, and the frequency of these words. We apply statistical methods to these textual data in order to account for these differences in meaningful ways.
Using text as data to extract relevant social or political information in systematic ways is an old practice in political science (e.g. Lasswell et al. 1949). Compared to classical content analysis, computer-assisted text analysis (CATA) has peaked recently due to the ease of access to massive amounts of textual data (Grimmer and Stewart 2013), with applications in the analysis of party manifestos (e.g. Klingemann et al. 2006), media political content (e.g., Sementko and Valkenburg 2000), actor influence in policy dynamics (Klüver 2009), or the analyisis of coalition dynamics (Falcó-Gimeno and Vallbé 2013).
A number of reasons support the use of computerized methods for textual data analysis over semi-automated or even manual methods. On one hand, CATA-based research strategies are less time- and resource consuming than classical content analysis, the latter being highly dependent upon human or semi-automatic codification of units of text (Budge et al. 2001; Klingemann et al. 2006; Jones and Baumgartner 2012), which in times of large amounts of available textual information turns out to be a serious shortcoming. On the other hand, CATA techniques are better equipped to deal with potential measurement problems that typically affect classical content analysis projects (Neuendorf 2002; Krippendorff 2004; Benoit and Laver 2007; Budge and Pennings 2007a, b; Benoit et al. 2009).
Text may be analysed automatically at different levels responding to the research purpose at hand. Lower units such as words, sentences or text chunks are often used to account for the identification of semantic features within relatively extensive corpora, while whole documents (be they simple queries, court decisions or party manifestos) are usually taken for classification and scaling. In particular, Natural Language Processing (NLP), Machine Learning, and Text Mining techniques (e.g., multiple correspondence analysis, principal components analysis, multidimensional scaling and hierarchical clustering) have been widely used for topic identification (Lebart and Salem 1988), semantic extraction (Reinert 2000; Schonhardt-Bailey 2005, 2008), semi-automated dictionary construction (Young and Soroka 2012), and document scaling and classification (Srivastava and Sahami 2009; Falcó-Gimeno and Vallbé 2013).
Table 5.2
Descriptive statistics of the textual corpora used in the analysis
Corpora | N docs | Min. | Mean | Median | Max. | Std. Dev. | Tokens | Types |
|---|---|---|---|---|---|---|---|---|
On call | 110 | 21 | 664.1 | 459 | 3692 | 742.7 | 73,048 | 3290 |
Civil | 111 | 5 | 380.5 | 115 | 5027 | 782.4 | 36,147 | 2685 |
Criminal | 109 | 11 | 454.8 | 192.5 | 3339 | 634.3 | 42,748 | 2925 |
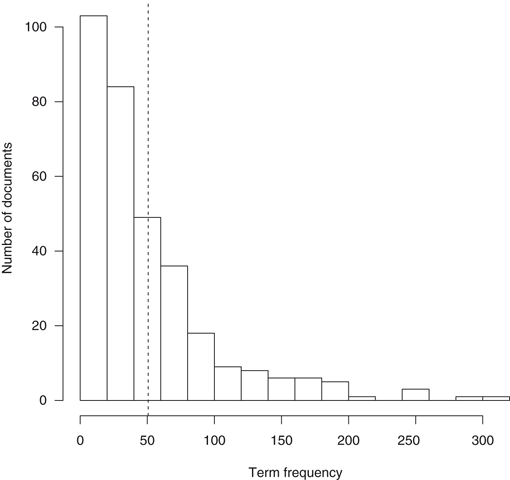
Regardless of the method applied, though, we must begin with a basic description of our textual data. To this effect, Table 5.2 presents basic descriptive statistics based on the word frequency of each document of the three corpora. We observe, first, that the On-call corpus is by far the larger of the three, with just above 73,000 word occurrences (tokens) and 3290 different words (types). Accordingly, the documents within the On-call corpus present a higher average frequency. Nevertheless, the three corpora have some similarities. First, all three present large differences regarding the word count of their documents. Note that in three cases there are documents with a very low word count (e.g., there is a document with just five words in the Civil corpus), and documents with a very large number of words (the larger document in the Civil corpus has 5027 words). The fourth and fifth columns of the table present measures of concentration. The fact that the median number of words is larger than the mean indicates a larger number of low-frequency documents in all three corpora. The standard deviation indicates the average distance between document frequencies and the mean frequency.
In order to compare the content of the documents through statistical methods to textual data we adopt the Bag of Words (or Vector Space) Model, that represents documents as vectors in a common vector space and is widely used in text mining and information retrieval (Salton et al. 1975; Baeza-Yates and Ribeiro-Neto 1999; Manning and Schütze 1999; Jakulin and Buntine 2004; Manning et al. 2008; Fortuna et al. 2009). Consider a corpus D that contains a number n of documents d:
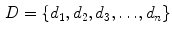
In turn, each document d has a number m of terms t:
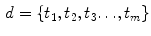
Each term t occurs with frequency