A Decision-Analytic Approach to Adaptive Resource Management
Resource problem
Goal
Source
Harvesting
Sustainable use
Translocation
Endangered species persistence
Tenhumberg et al. (2004)
Pest management
Control
Management of human disturbance
Endangered species occupancy
Martin et al. (2011)
Fire management
Biodiversity conservation
Endangered species persistence
Johnson et al. (2011)
Forest management
Endangered species persistence
Moore and Conroy (2006)
Reservoir management
Water supply
Landscape reconstruction
Endangered species persistence
Westphal et al. (2003)
Allocation of conservation resources
Biodiversity conservation
Wilson et al. (2006)
Dynamic optimization methods , with their focus on recurrent decisions and the uncertainties attendant to future outcomes, are particularly well suited for formulating adaptive management strategies. They combine models of ecological system change with objective functions that value present and future consequences of alternative management actions. The general resource management problem involves a temporal sequence of decisions, where the optimal action at each decision point depends on time and/or system state (Possingham 1997). The goal of the manager is to develop a decision rule (or management policy) that prescribes management actions for each time and system state that are optimal with respect to the objective function. Under the assumption of Markovian system transitions, the optimal management policy satisfies the Principle of Optimality (Bellman 1957), which states that:
An optimal policy has the property that, whatever the initial state and decision are, the remaining decisions must constitute an optimal policy with regard to the state resulting from the first decision.
A key advantage of dynamic optimization is its ability to produce a feedback policy specifying optimal decisions for possible future system states rather than expected future states (Walters and Hilborn 1978). In practice this makes optimization appropriate for systems that behave stochastically, absent any assumptions about the system remaining in a desired equilibrium or about the production of a constant stream of resource returns. The analysis of recurrent decision problems with dynamic optimization methods also allows for the specification of the relative value of current and future management returns through discount rates. By properly framing problems, dynamic optimization methods have been used successfully to address a broad array of important conservation issues. It seems clear from the wide applicability of these methods that it is not optimization per se that leads to unsustainable policies as some authors seem to suggest (e.g., Walker and Salt 2006), but rather the use of outdated methods that assume the existence of equilibrium in resource state or use, and the tendency to heavily discount the future.
A framework for dynamic optimization requires specification of (1) an objective function for evaluating alternative management policies; (2) predictive models of system dynamics that are formulated in quantities relevant to the stated management objectives; (3) a finite set of alternative management actions, including any constraints on their use; and (4) a monitoring program to follow the system’s evolution and responses to management. More formally, let:
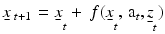
(1)
characterize system dynamics, where  represents the system state at time
represents the system state at time  and
and  and
and 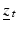 represent management actions and environmental variation respectively. Random demographic and environmental variation induces Markovian transition probabilities
represent management actions and environmental variation respectively. Random demographic and environmental variation induces Markovian transition probabilities 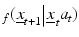 . Let policy
. Let policy 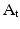 specify an action for every system state
specify an action for every system state 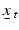 at every time in the time frame
at every time in the time frame 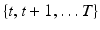 . Benefits and costs attend management actions, which are included in returns
. Benefits and costs attend management actions, which are included in returns 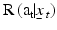 that in turn are accumulated in an objective or value function:
that in turn are accumulated in an objective or value function:
represents the system state at time and and represent management actions and environmental variation respectively. Random demographic and environmental variation induces Markovian transition probabilities . Let policy specify an action for every system state at every time in the time frame . Benefits and costs attend management actions, which are included in returns that in turn are accumulated in an objective or value function: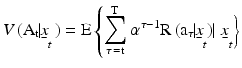
(2)
where the expectation is with respect to stochastic influences on the process and 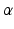 discounts future returns. This function can be decomposed into current returns and future values by:
discounts future returns. This function can be decomposed into current returns and future values by:
discounts future returns. This function can be decomposed into current returns and future values by: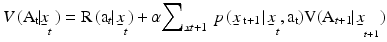
(3)
which makes clear that future values are conditioned on the effect of current actions on future states. A value 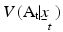 can be obtained for every possible policy
can be obtained for every possible policy 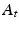 over the time frame, and the optimal policy satisfies:
over the time frame, and the optimal policy satisfies:
can be obtained for every possible policy over the time frame, and the optimal policy satisfies: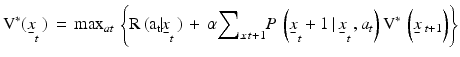
(4)
(Bellman 1957, Puterman 1994, Bertsekas 1995). The discount factor 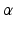 in Eqs. 3 and 4 highlights the influence of myopia in decision making, i.e., the effect of discounting the future relative to the present.
in Eqs. 3 and 4 highlights the influence of myopia in decision making, i.e., the effect of discounting the future relative to the present.
in Eqs. 3 and 4 highlights the influence of myopia in decision making, i.e., the effect of discounting the future relative to the present.A key consideration in dynamic optimization of natural resource problems is the uncertainty attendant to management outcomes, which adds to the demographic and environmental variation of stochastic resource changes. This uncertainty may stem from errors in measurement and sampling of ecological systems (partial system observability), incomplete control of management actions, and incomplete knowledge of system behavior (structural uncertainty) (Williams et al. 1996). A failure to recognize and account for these uncertainties can significantly depress management performance and in some cases can lead to severe environmental and economic losses (Ludwig et al. 1993). In recent years there has been an increasing emphasis on methods that can account for uncertainty about the dynamics of ecological systems and their responses to both controlled and uncontrolled factors (Walters 1986, Williams 2001).
Model uncertainty , an issue of special importance in adaptive management, can be characterized by continuous or discrete probability distributions of model parameters, or by discrete distributions of alternative model forms that are hypothesized or estimated from historic data (e.g., Walters and Hilborn 1978, Johnson et al. 1997). Important advances have followed from the recognition that these probability distributions are not static, but evolve over time as new observations of system behaviors are accumulated from the management process. Indeed, the defining characteristic of adaptive management is the attempt to account for the temporal dynamics of this uncertainty in making management decisions (Walters 1986, Williams 2001, Allen et al. 2011).
It thus appears adaptive management and decision analysis have been self-reinforcing concepts, with one driving advances in the other and both playing increasingly important roles in how resource managers approach decision making. However, we suggest here that adaptive management efforts can fail if an adaptive approach is advocated before there is a careful, systematic analysis of the decision problem. Not all problems are suitable for adaptive management (Gregory et al. 2006, Allen and Gunderson 2011), and the deliberate structuring of a problem based on the principles of decision analysis can help discern good from bad candidates. For example, if the primary impediment to decision making is a conflict of values, adaptive management may have little to offer. Its use under these circumstances can become little more than displacement behavior that avoids the difficult challenges of developing more effective institutional and governance structures to resolve disputes (Susskind et al. 2010). Nor is an adaptive approach needed if management choices are insensitive to structural sources of uncertainty (although even here dynamic optimization may be useful). Finally, a failure of management choices to discriminate among competing system models means that adaptive management will not result in learning, an essential element of adaptive decision making.
Decision analysis provides a systematic framework for exploring these issues, and it is difficult to imagine how adaptive management could be planned or implemented absent this structure. In this light, perhaps it is not surprising that the clarion call for adaptive resource management over 30 years ago was followed more by an expanding use of decision analysis than by bona fide examples of system probing and management experiments. Fortunately, that focus has taught us much about how best to proceed with management problems that are characterized by various sources and degrees of uncertainty. In turn, a focus on learning has spurred innovations in decision analysis that make it increasingly useful for real-world problems in natural resource management.
Advances in Decision Analysis
Walters (1986) recognized the potential of dynamic optimization to identify strategies that account for uncertainty in system dynamics. His insight provided a framework by which managers could effectively attack the “dual-control problem,” in which management for short-term objective values must somehow be balanced with the learning necessary to improve future returns. At the time, the additional dimensionality introduced by the need to track structural uncertainty along with system state made almost all realistic problems computationally intractable. However, over the last three decades the development of efficient computing algorithms and increases in computer speed and memory have dramatically expanded the class of feasible resource problems.
Computing Algorithms
Many important advances have followed from acknowledgment that the process controlling state transitions is uncertain, and that uncertainty can be incorporated directly into decision making. Here we express uncertainty with alternative system models that are characterized by parameter 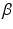 :
:
: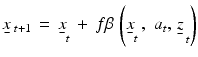
(5)
with random demographic and environmental variation inducing model-specific Markovian transition probabilities: 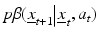 . Policy value is again given in terms of accumulated returns, except in this case the returns are averaged over alternative models:
. Policy value is again given in terms of accumulated returns, except in this case the returns are averaged over alternative models:
. Policy value is again given in terms of accumulated returns, except in this case the returns are averaged over alternative models: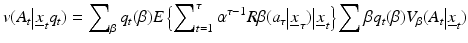
(6)
The distribution 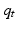 represents model-specific probabilities that evolve through time according to Bayes theorem:
represents model-specific probabilities that evolve through time according to Bayes theorem:
represents model-specific probabilities that evolve through time according to Bayes theorem: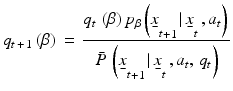
(7)
with
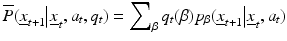
(8)
The optimal policy satisfies:
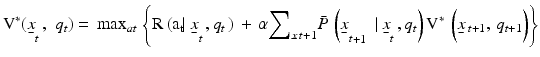
(9)
with
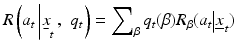
(10)
and
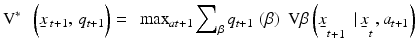
(11)
(Williams 2009). Note that current returns in Eq. 9 are averaged using the prior probabilities of the alternative models (Eq. 10), whereas future returns are weighted by the posterior probabilities (Eq. 11). A management action is chosen at each point in time depending on resource state and the parameter state 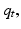 and the action in turn influences future resource state as well as changes in the parameter state. Optimal management consists of actions that maximize objective returns, not learning per se, with model discrimination (i.e., learning) pursued only to the extent that it increases long-term returns. This approach can be described as active adaptive management, in that it explicitly accounts for the effect of management actions on learning and the effect of that learning on future returns. We characterize this form of adaptive management as “learning while doing,” as opposed to an experimental approach to adaptive management (Walters and Holling 1990, Walters and Green 1997) that might be characterized as “learn, then do.”
and the action in turn influences future resource state as well as changes in the parameter state. Optimal management consists of actions that maximize objective returns, not learning per se, with model discrimination (i.e., learning) pursued only to the extent that it increases long-term returns. This approach can be described as active adaptive management, in that it explicitly accounts for the effect of management actions on learning and the effect of that learning on future returns. We characterize this form of adaptive management as “learning while doing,” as opposed to an experimental approach to adaptive management (Walters and Holling 1990, Walters and Green 1997) that might be characterized as “learn, then do.”
and the action in turn influences future resource state as well as changes in the parameter state. Optimal management consists of actions that maximize objective returns, not learning per se, with model discrimination (i.e., learning) pursued only to the extent that it increases long-term returns. This approach can be described as active adaptive management, in that it explicitly accounts for the effect of management actions on learning and the effect of that learning on future returns. We characterize this form of adaptive management as “learning while doing,” as opposed to an experimental approach to adaptive management (Walters and Holling 1990, Walters and Green 1997) that might be characterized as “learn, then do.”The calculation of optimal adaptive management policies can impose large demands on computing resources. One way to relieve those demands is to use passive adaptive optimization, an approach that accounts for structural uncertainty while eliminating the need to carry distribution 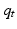 in the optimization algorithm. In this case, at each time
in the optimization algorithm. In this case, at each time  is treated as fixed and is used in both terms of Eq. 9. As with actively adaptive optimization,
is treated as fixed and is used in both terms of Eq. 9. As with actively adaptive optimization,  is updated periodically using a comparison of observed and model-predicted system responses, but in passive adaptive management that updating is not anticipated in the optimization algorithm (Williams et al. 2002). This approach is quite different from the more prominent description of passive adaptive management in the literature, in which management actions are derived using the single best model and then management experience is used to revise or replace it (Walters and Hilborn 1978, Schreiber et al. 2004, Williams 2011a).
is updated periodically using a comparison of observed and model-predicted system responses, but in passive adaptive management that updating is not anticipated in the optimization algorithm (Williams et al. 2002). This approach is quite different from the more prominent description of passive adaptive management in the literature, in which management actions are derived using the single best model and then management experience is used to revise or replace it (Walters and Hilborn 1978, Schreiber et al. 2004, Williams 2011a).
in the optimization algorithm. In this case, at each time is treated as fixed and is used in both terms of Eq. 9. As with actively adaptive optimization, is updated periodically using a comparison of observed and model-predicted system responses, but in passive adaptive management that updating is not anticipated in the optimization algorithm (Williams et al. 2002). This approach is quite different from the more prominent description of passive adaptive management in the literature, in which management actions are derived using the single best model and then management experience is used to revise or replace it (Walters and Hilborn 1978, Schreiber et al. 2004, Williams 2011a).One of the most successful examples of large-scale adaptive management is the U.S. Fish and Wildlife Service’s program to regulate mallard (Anas platyrhynchos) harvests, which relies on passive adaptive optimization (Johnson and Williams 1999, Nichols et al. 2007). The optimization algorithm explicitly accounts for environmental variation and partial controllability of harvests, and admits four alternative models of population dynamics, with process error attendant to each. In 1995, the prior probability for each of the four models was set to 0.25 by consensus of the management community. Probabilities associated with the alternative models have changed substantially since implementation of the program and, as a result, there has been considerable change in management policy (Fig. 5.1) (Johnson 2010). The change in harvest policy from 1995 to 2007 is a striking example of the efficacy of a passive adaptive management program that involves model averaging to calculate policies, and a monitoring program to periodically update the probabilities of alternative models .
Fig. 5.1
(a) The sport harvest of mallards in the United States is a long-running, successful application of adaptive management. At right are the probabilities of four alternative models of mallard population dynamics, which have been updated each year based on Bayes’ theorem and a comparison of model-specific predictions of population size with that observed via a monitoring program (from Johnson 2010) (b) At left are the passively adaptive, regulatory harvest policies for mallards based on four alternative models of population dynamics, conditioned on prior (1995) and posterior (2007) model probabilities. The cross-hairs on each plot indicate the expected mean (plus and minus one standard deviation) of population size and pond numbers. The optimal policies seek to balance accumulated harvest with a desire to keep the population from falling below a goal of 8.8 million (from Johnson 2010)
Recent Advances
Thus far we have focused on resource systems in which system state 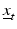 is completely observable and system dynamics can be characterized by stationary Markov chains. These simplifying assumptions greatly facilitate the calculation of optimal policies, but the potential for suboptimal management performance can be significant in some natural resource problems. There is active interest in ways to relax the assumption of a completely observable system while maintaining computational tractability. For a problem involving a space of discrete system states, partial observability transforms the problem into a partially observable Markov decision process (POMDP) with a continuous space of state probability distributions at each time (Williams et al. 2011). POMDP approaches appear to be particularly applicable to questions of monitoring design (White 2005, Chades et al. 2008). The development and subsequent modification of monitoring programs has been an under-scrutinized element of adaptive management efforts (Nichols and Williams 2006, Lyons et al. 2008). More generally, similarities in the way partially observed and structurally uncertain systems are modeled allow computing algorithms for POMDPs to be applicable for resolving structural uncertainties in systems with large dimensionality in the distribution
is completely observable and system dynamics can be characterized by stationary Markov chains. These simplifying assumptions greatly facilitate the calculation of optimal policies, but the potential for suboptimal management performance can be significant in some natural resource problems. There is active interest in ways to relax the assumption of a completely observable system while maintaining computational tractability. For a problem involving a space of discrete system states, partial observability transforms the problem into a partially observable Markov decision process (POMDP) with a continuous space of state probability distributions at each time (Williams et al. 2011). POMDP approaches appear to be particularly applicable to questions of monitoring design (White 2005, Chades et al. 2008). The development and subsequent modification of monitoring programs has been an under-scrutinized element of adaptive management efforts (Nichols and Williams 2006, Lyons et al. 2008). More generally, similarities in the way partially observed and structurally uncertain systems are modeled allow computing algorithms for POMDPs to be applicable for resolving structural uncertainties in systems with large dimensionality in the distribution 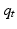 (Williams 2009, 2011b). Finding efficient computing algorithms for POMDPs is an active area of research (e.g., Pineau et al. 2006).
(Williams 2009, 2011b). Finding efficient computing algorithms for POMDPs is an active area of research (e.g., Pineau et al. 2006).
is completely observable and system dynamics can be characterized by stationary Markov chains. These simplifying assumptions greatly facilitate the calculation of optimal policies, but the potential for suboptimal management performance can be significant in some natural resource problems. There is active interest in ways to relax the assumption of a completely observable system while maintaining computational tractability. For a problem involving a space of discrete system states, partial observability transforms the problem into a partially observable Markov decision process (POMDP) with a continuous space of state probability distributions at each time (Williams et al. 2011). POMDP approaches appear to be particularly applicable to questions of monitoring design (White 2005, Chades et al. 2008). The development and subsequent modification of monitoring programs has been an under-scrutinized element of adaptive management efforts (Nichols and Williams 2006, Lyons et al. 2008). More generally, similarities in the way partially observed and structurally uncertain systems are modeled allow computing algorithms for POMDPs to be applicable for resolving structural uncertainties in systems with large dimensionality in the distribution (Williams 2009, 2011b). Finding efficient computing algorithms for POMDPs is an active area of research (e.g., Pineau et al. 2006).To date, most of the work on both partially observable and structurally uncertain systems has assumed Markov state transitions that are stationary over time. Non-Markovian systems, which contain time-lags or other forms of history-dependent transitions, can greatly increase computational demands, but there are no theoretical obstacles to including non-Markovian transitions in state dynamics (Williams 2007). Similarly, non-stationary dynamics can in principle be handled in computing optimal management policies, assuming analysts are clever enough to capture plausible ideas about the degree and rate of change in a set of alternative models (Conroy et al. 2011). A shift in system dynamics is the signature feature of climate change , and dynamic optimization offers a way to plan and adapt conservation strategies in the presence of a changing but uncertain climate (McDonald-Madden et al. 2011, Nichols et al. 2011).
Finally, we recognize that decision analysis focusing on maximizing the expected return from a management process is not possible if the probabilities attendant to stochastic outcomes cannot be specified or the values of those outcomes cannot easily be assigned (or agreed upon). Information-gap decision theory (Ben-Haim 2001) replaces the focus on management alternatives that produce the highest return with one that seeks alternatives that are robust to uncertainty in outcomes or values. In a context of static decision making with model uncertainty, the necessary elements for info-gap are: (1) a “guesstimate” 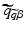 of a probability distribution for the models (i.e., some notion about model credibilities); (2) a value function
of a probability distribution for the models (i.e., some notion about model credibilities); (2) a value function 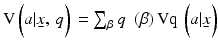 that averages model-specific values; (3) a minimum performance criterion
that averages model-specific values; (3) a minimum performance criterion 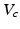 for the value function; and (4) an uncertainty horizon
for the value function; and (4) an uncertainty horizon 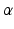 that defines a range of model states about
that defines a range of model states about 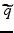 by:
by:
of a probability distribution for the models (i.e., some notion about model credibilities); (2) a value function that averages model-specific values; (3) a minimum performance criterion for the value function; and (4) an uncertainty horizon that defines a range of model states about by: